这篇文章主要介绍经典的分布式快照算法——Chandy Lamport Algorithm.
引入

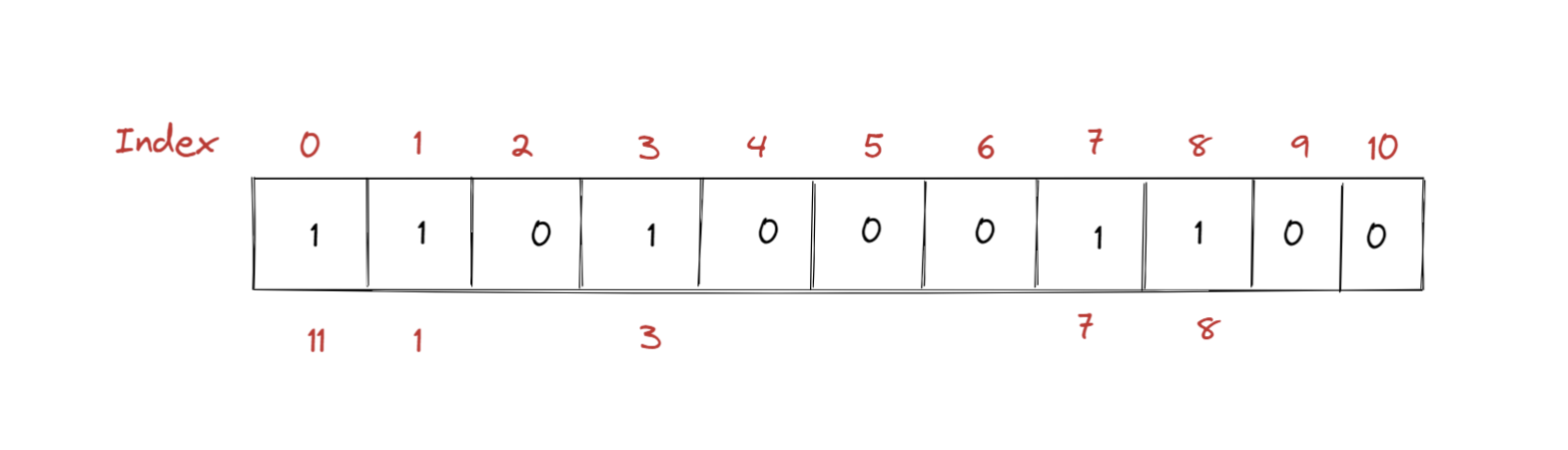
比如在我们上面这张图里面,我们可以很容易知晓各国领导人的当前状态,因为无论从时间上还是空间的角度而言,他们都是同步好了,也就是说我们知道了在这一时刻每个领导人的状态。
但是如果这些领导人他们各自在家,我们有该如何去获取这样一个快照呢?而且同时我们实际需要的快照会更加复杂些,比如目前领导者之前通话说的内容也需要记载。
因此我们需要一个全局的快照来记录一个全局的状态。
对于一个分布式系统而言,会有许多应用程序分布在不同的物理机上。这些应用程序进程之间的交互则是使用channel(通道),那么基于这样的一个抽象的模型,我们定义我们的全局快照如下:
1
| 一个全局快照需要记录每一个进程的本地状态(例如程序变量等)以及每一个channel的状态。
|
那么我们用这个快照的好处有哪些呢?
1
2
3
4
5
| 1.用作检查点:当出现应用程序失败时可以重启恢复
2.垃圾收集(GC):可以讲不再用到的数据删除
3.死锁检测:可以检测当前应用程序状态是否出现死锁
4.用于调试:使用快照讲更优于打印的方式来进行调试
.......
|
那么快照的生成我们需要的各个进程的同一时刻的状态,且要是全局的,但是我们怎么去保证这样一个同一时刻呢?因为存在时钟倾斜的问题,我们很难保证做到这一点,也就是说同步快照是很难做到的。
1
2
| 由于无法做到"同时",因此在时间差上就可能有状态的变化,任何进程接受或者发送消息或者做了
其它什么事情状态都将被认为改变了。
|
Chandy Lamport Algorithm
为了解决这个时钟的问题,于是我们有了这个算法。
1
2
3
4
5
6
7
8
9
10
11
12
| 系统模型:
待解决的问题:
记录一个全局的快照(记录每个进程和每个channel的状态)
模型:
1.系统当中有N个进程,并且都不会失败
2.在每个Process对之间都会有两个单向的FIFO的通道(P1--->P2 和 P2---->P1)
3.所有的消息都会到达,并且完好无损(intact),没有重复
要求:
1.生成快照不应该影响系统的正常运行
2.每个进程都可以自己记录自己的状态
3.可以分布式地去搜集这些状态
4.任何进程都可以初始化一个快照
|
初始化快照(快照的开始点)
1
2
3
| 对于进程Pi而言,它会记录自己的状态同时也会准备一个特殊的标记消息(marker message),然
后它会将这个标记消息发送给其它N-1个节点.接下来就会去记录所有从其它节点(也就是Cji,i!=j)
过来的消息(因为在channel里面的消息也是快照的一部分,这些消息暂留在channel)
|
传播快照
1
2
3
4
5
6
7
8
9
| 对于所有的进程它会对于收到的消息做一个识别.当它发现自己收到了一个marker message就会触发快照的
的执行.下面为了方便描述,我们考虑Pj,它的对应marker message的channel记作Ckj,代表数据从k流向j
如果收到marker消息时(这个标记消息是我们第一次收到的,如果重复收就不是这个条件了):
1.Pj记录自己的状态并标记Ckj为空
2.发送该marker message给所有其它N-1个节点
3.接下来开始去记录在Clj里面的暂留的消息(l!=j,l!=k,关于这里其实也没有那么严格
其实后那个例子在这一点也不是这么严格的,即使不遵守只要保证幂等也可以)
否则就将Ctj(t!=j)通道里面过来的消息记录到状态中(注意这里的记录状态按照我的理解应该
指的是普通的日志记录)
|
中断快照
1
2
| 当所有的进程都收到了marker message后并且自己的状态也记录好了,这时就会有一个
中央服务器来收集部分状态构建出一个全局的快照
|
算法例子
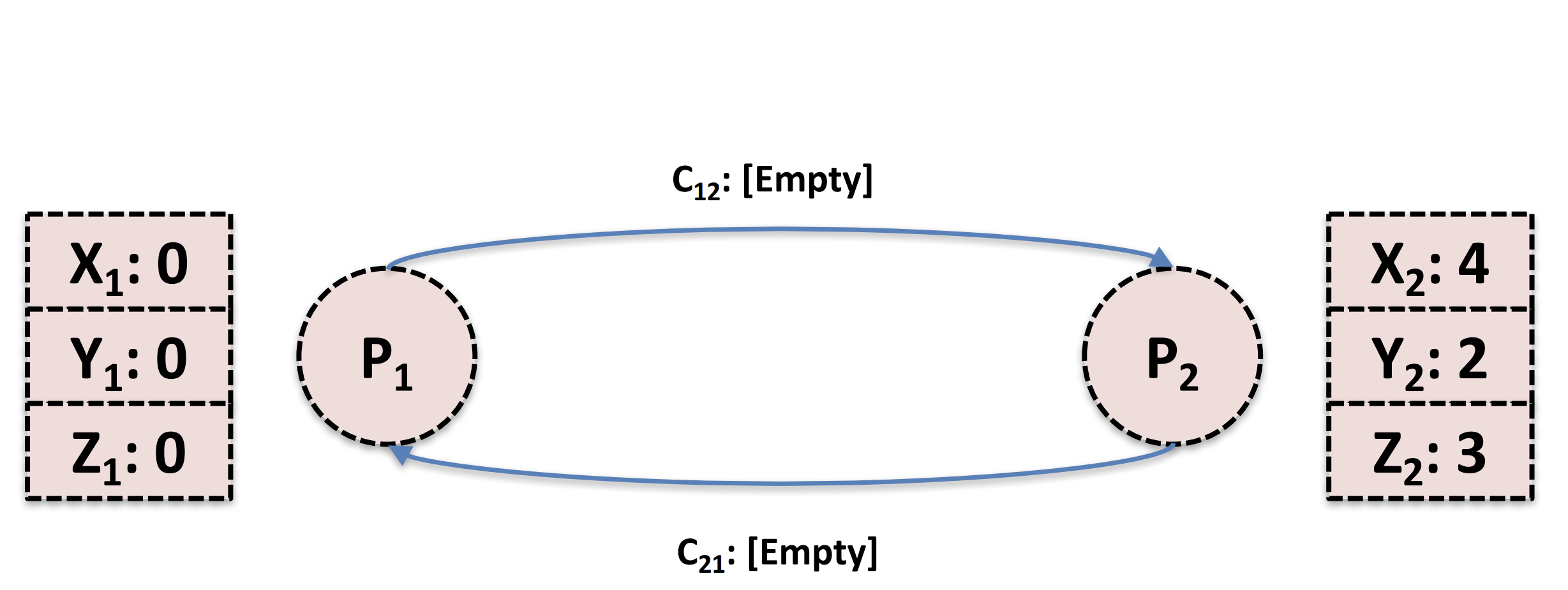
如上图时最开始的起始状系统状态,首先我们P1作为快照起始点,它会先记录自己的本地状态,如下,在记录完本地状态后就成为下图了(蓝色代表状态记录完毕)
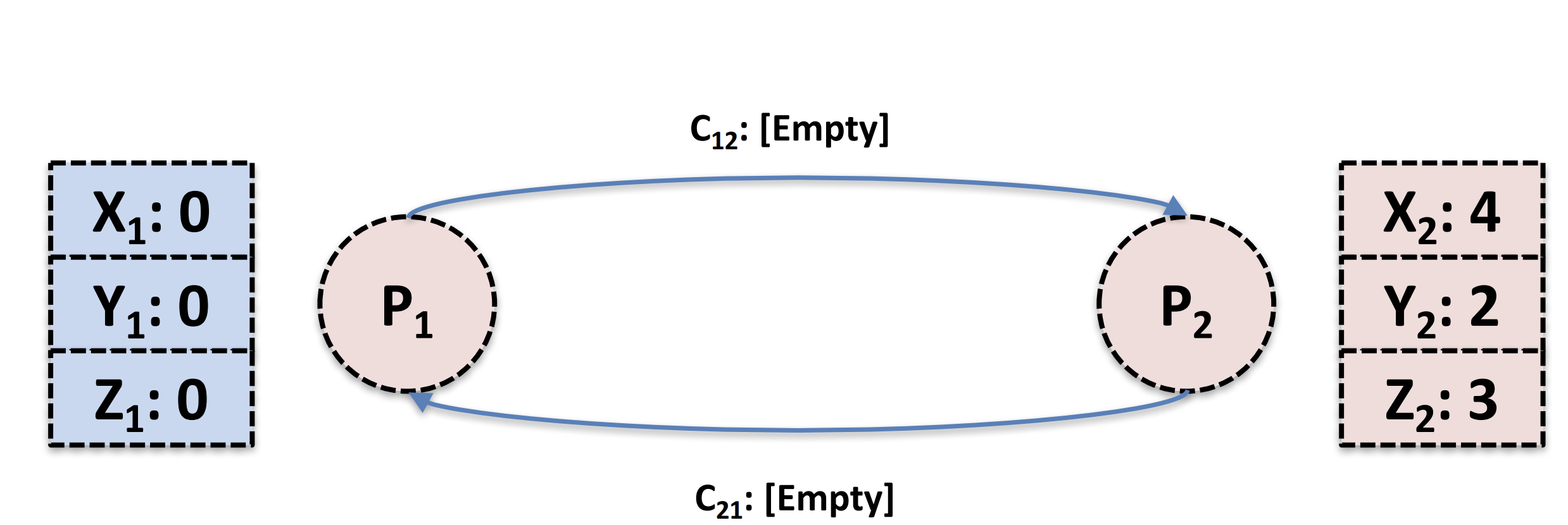
在达到上面这个图的系统状态后,在下图当中,此时P1发送了一条marker message,同时P2也发了一条消息到通道当中。
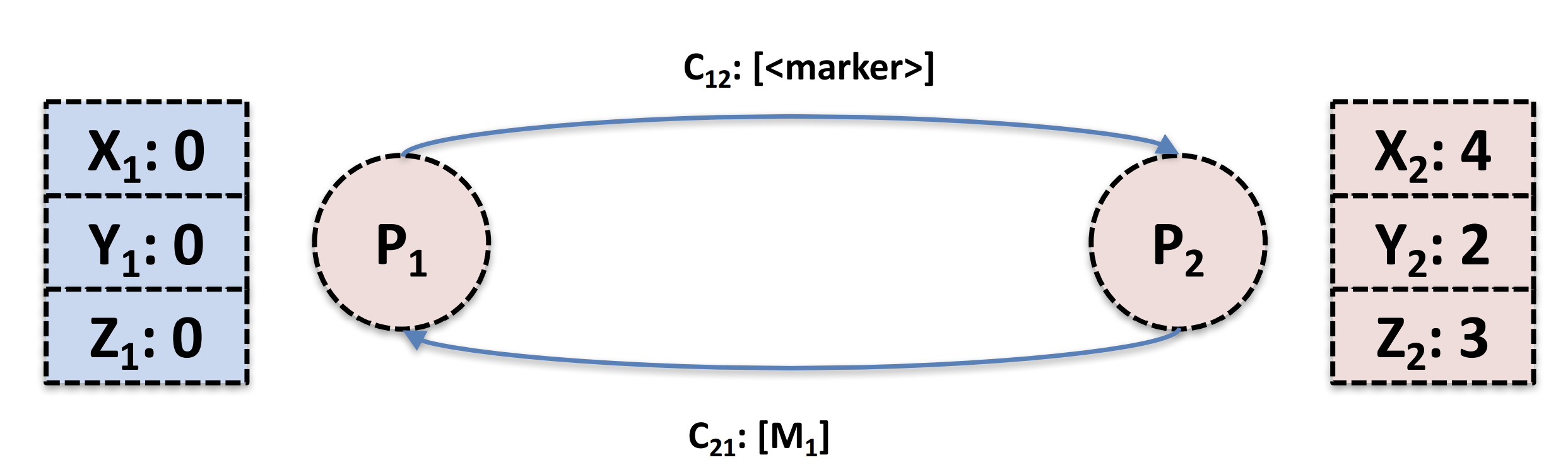
在下图当中,此时P1就会开始记录通道的消息(发送完marker message后),而P2在收到marker message后也将这个marker message广播出去了
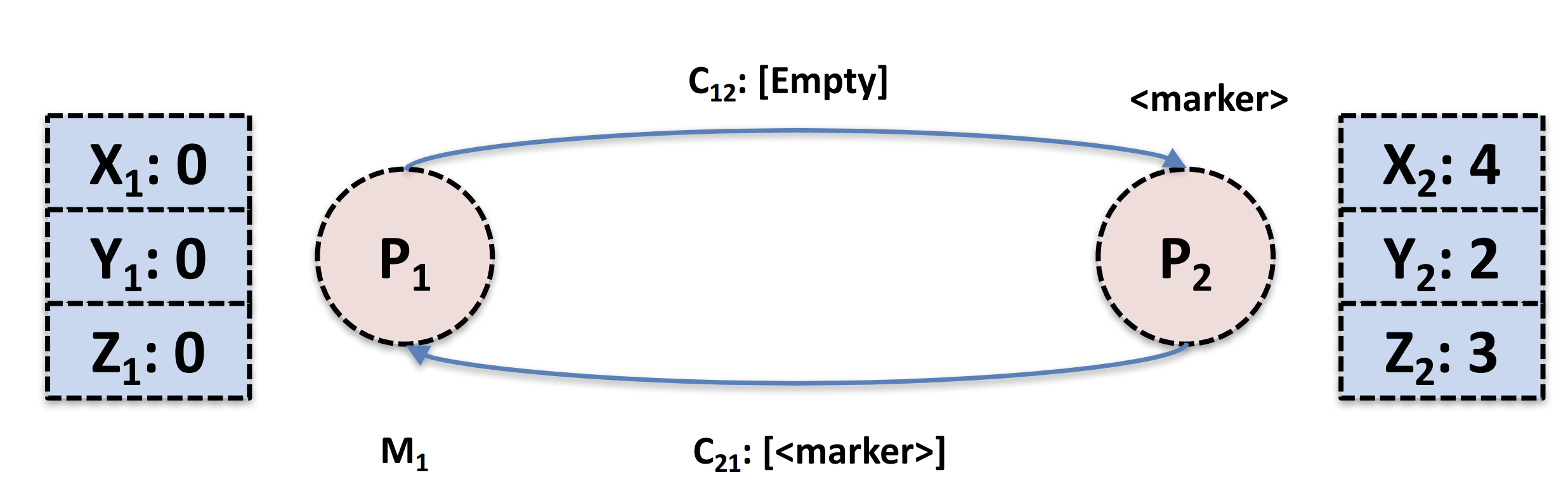
在上图当中P2收到了标记消息(第一次)就会记录本地状态,也会将通道C12标记为empty,同时记录C12里面滞留的消息(由于上C12上面实际上啥也没有了,所以实际没做啥),现在就变成了上面的系统状态了(蓝色区域代表都已经生成好的状态)
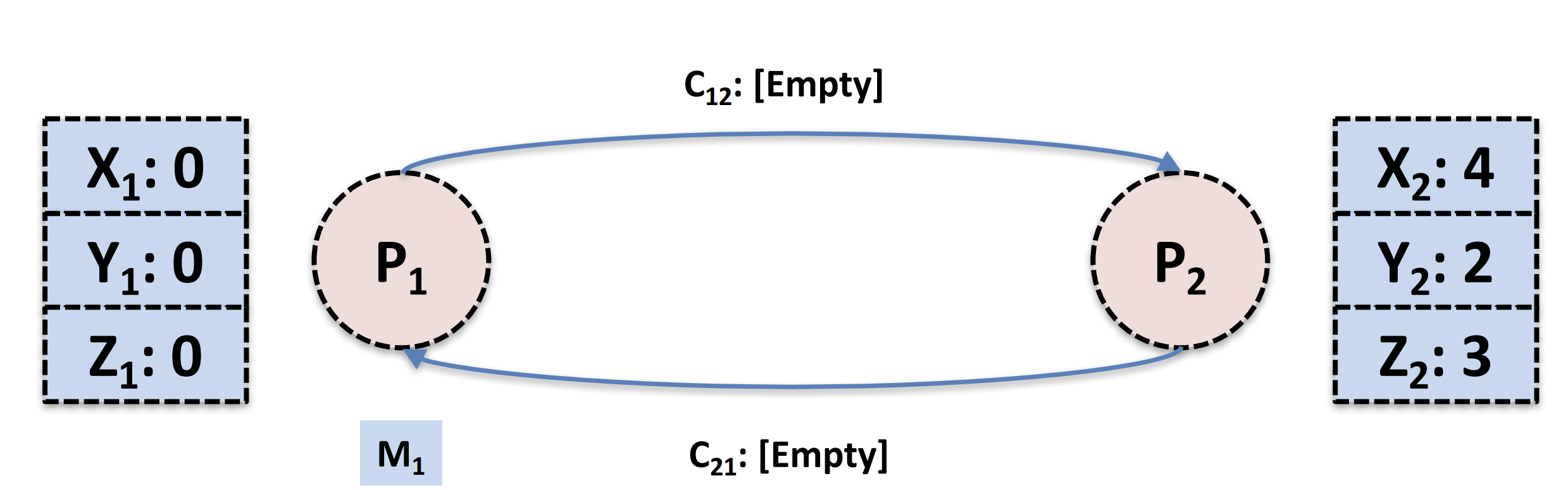
在上图当中,P1由于发完了标记消息后也会记录C21的消息,所以M1也被记录到状态当中,然后C21也被标记为empty
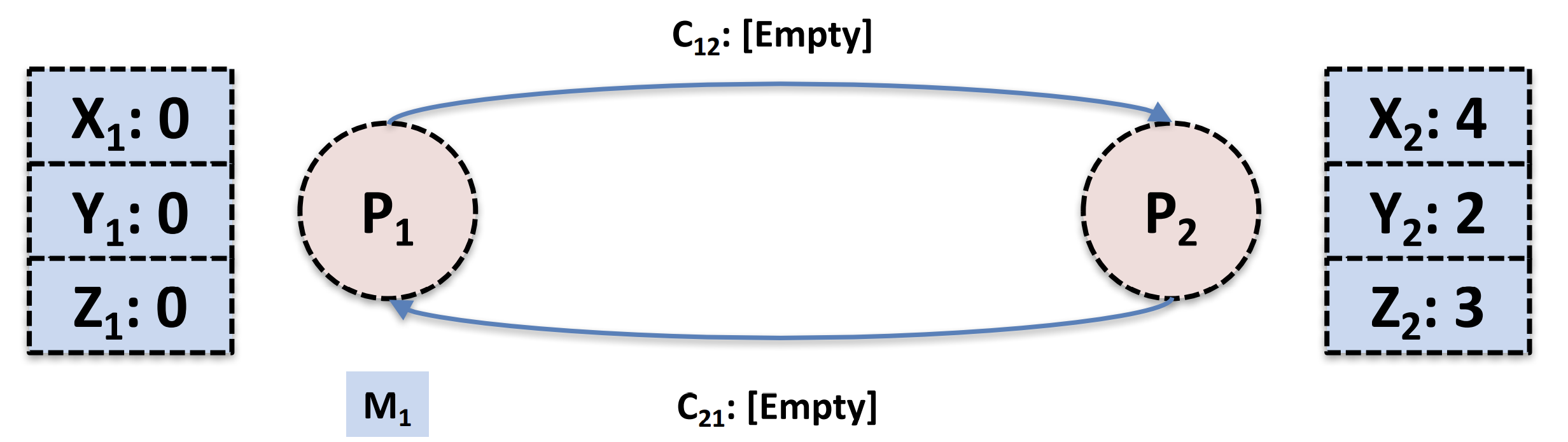
最后的结果就是上面蓝色部分整体构成一个全局的快照。
算法正确性证明
首先我们这个算法的目的是解决时钟倾斜的问题的,而实际上本算法是通过保证了一个因果一致性来另辟蹊径的。因此我们需要证明它的因果一致性。
1
2
3
4
5
| 1.如果事件发生在任意一个进程的快照之前,就称之为预快照(presnapshot),也就是
说这个事件也应当最后在我们的全局快照当中
2.如果一个事件发生任意一个进程快照之后,那么就是称之为后快照(postsnapshot),也
就是说这个事件不应该出现在我们的全局快照当中
3.如果A发生在预快照B之前,那么A也是预快照
|
下面开始证明:
1
2
3
4
5
6
7
8
| 1.如果A和B事件都发生在同一个进程当中,那么我们无需担心在生成快照时出问题
2.如果时不同的进程,那么假设我们在进程P上发送事件是A,而在Q上相应的接受事件是B,
如果说B是presnapshot,那么说明Q就还没有收到marker message(收到marker mess
age就代表快照开始了),那么P肯定也还没有发送marker message(发送marker mess
age就代表快照开始了),这说明了A肯定也是一个presnapshot
3.当B是postsnapshot同样可以证明A也是postsnapshot
综上所述我们证明了快照的正确性
|